 微信扫一扫
微信扫一扫


热门交叉专业生物信息专业录取g5伦敦大学学院
背景介绍
申请难点
留学规划与提升
案例解析:
硬件:
均分:86.92 无gmat GRE 与IELTS
本科院校:华中农业大学
软件:
1.项目经历:研究转座子对基因表达量的影响
2.实习经历:
深圳华大基因学院实习
3.比赛:
美赛、全国数学建模大赛等等
本科专业:生物信息
研究生申请专业:生物信息相关的专业!
留学指导老师:鲁铃 Ivy
录取院校:
1、伦敦大学学院
专业:药物设计
必修单元
- 生物信息学和结构生物学
- 目标识别和高通量筛选
- 化学信息学与计算机药物设计
- 生物分子作为治疗药物 - 抗体,siRNA和干细胞
- 生物物理筛选方法,蛋白质NMR和表型筛选
- 基于片段的药物设计(FBDD)
- 目标选择 - 科学理由
- 目标选择 - 商业和知识产权
没有选修课
论文
2、爱丁堡大学
专业:生物信息
必修课程:
- 生物信息学编程与系统管理
- 生物信息学研究提案
- 硕士学位论文(生物信息学)
- 统计与数据分析
选修课程:
- 生物信息学1
- 人机交互
- 生物细胞中的信息处理
- Java编程简介
- 分子建模与数据库挖掘
- 实用系统生物学
- 定量药物结合
- 生物信息学2
- 生物信息学算法
- 比较和进化基因组学
- 药物发现
- 功能基因组技术
- 药物发现网站和数据库设计简介
- 分子系统发育学
- 下一代基因组学
- 软件架构,流程和管理
- 软件开发
研究
3、曼彻斯特大学
4、伦敦国王学院
offer展示:



院校解读
留学方案
案例分析
专业介绍:
生物信息学是一门交叉学科,它将计算机技术、统计学方法以及数学算法等应用到生物学研究当中。这门学科的产生也是一种必然趋势,毕竟测序技术发展那么快,分子生物学和遗传生物学的信息量爆炸式增长。举个简单的例子来说现在随便一个测序至少6个样本,每个样本3万个探针信息,全球那么多人做测序,这信息量就跟海一样,生物信息学就是为了把这海变成湖,变成池塘。另一方面,遗传学本身的信息量就很大,比如人类基因组有30亿对碱基,2.5万的基因,所以生物信息学的一个重要应用就是建立各种各样的数据库,来实现信息共享,毕竟一个人穷尽一生的精力可能也就研究几个基因,但是全球这么多人共同努力,这2.5万个基因就变得不那么难了。
生物信息学分析就是生物学中的大数据分析,这项分析的好坏很大程度上取决于你对数据筛选的把控,你就是马云手下的投资分析师,一个个基因就像是各种投资项目一样,选哪个就看你分析的怎么样。
另外,自己动手只能完成少量实验,实验过程中样本数量多少、是否双盲实验、是否随机分组等等因素都会影响到实验的准确性,而生物信息学中大数据背景下,随机产生的误差反而会变小。
所以说,生物信息学的方法是强有力的工具,运用得当你将如虎添翼。
基因组 (Genome)
“基因组”这个概念最早由植物学家Hans Winkler提出,他当时用“基因组”这个词来描述所有染色体的集合。其实当时在科学界也存在其它的组学概念,比如用来描述所有生命体集合的生物组学(biome)和囊括所有根系(root)的根组学(rhizome)等。这些单词不约而同地都以“ome”这个希腊语后缀做结尾,就是取其具有某种性质的意思——一大群具有同样性质的个体的集合。随后,人类基因组计划(Human Genome Project)等重大科研项目的巨大影响力使得“基因组”这词火了起来。所以从“组学”这个后缀的本意来看,如果我们提到某种组学,那么指的应该是一个全新的科学领域,而不是某些既有元素的重新排列组合而已。然而由于装逼心理的作祟,大量无聊而逗逼的“组”涌现了出来,有人调侃说,如果把放屁相关的基因定义一个集合,可以叫“放屁组”。
现在基因组被定义为一个细胞或者生物体所携带的一套完整的单倍体序列,包括全套基因和间隔序列。以水果摊为例,比如说这个水果摊卖苹果、香蕉和西瓜,而这些水果都是装在果篮里的,水果组就是指苹果、香蕉和西瓜以及装它们的果篮,其中苹果、香蕉和西瓜就是常说的编码基因,能够卖给别人赚钱(编码蛋白),果篮则是非编码RNA,店里的苹果数量多,这叫作基因丰度高,而卖出去西瓜多,这叫作基因表达丰度高,基因表达丰度由基因丰度和启动子强弱共同决定,夏天到了(干扰条件)大家都想吃西瓜(启动子强),西瓜自然会卖的多一些(基因表达丰度高)。

蛋白质组 (Proteome)
蛋白质组同为组学中的概念,指的是细胞或组织表达的蛋白质的全部集合。定义这么一个集合也是为了研究的时候方便,同时也是为了强调蛋白质之间的相互联系。蛋白质组学可以大致分为结构蛋白质组学和功能蛋白质组学两方面。本宫上学的时候,研究蛋白质组学的老师手下的学生都十分羡慕那些做基因组学的,因为蛋白质组学实在太复杂了,光从一个基因可以对应多个蛋白质这一点来说,蛋白质组学的规模就比基因组学大得多,更不用说蛋白质的结构复杂程度远远高于RNA。
基因本体论 (Gene Ontology, GO)
本体论这个词一看就逼格很高的样子,源于哲学,本体论用于描述事物的本质,所以基因本体论就是为了描述基因的本质。GO从三个方面对基因的本质进行描述,1)细胞组分(Cellular Component, CC):一般用来描述基因作用的位置,比如说高尔基体,内质网这样的;2)分子功能(Molecular Function):可以描述为分子水平的活性,如催化或结合活性;3)生物学过程:比如说蛋白质磷酸化,细胞粘附都是生物学过程。简单地说,GO就像是给基因贴标签进行注释,比如说给X湿兄贴标签,出没地点——小张聊科研(CC),文风诙谐幽默(MF),能够让大家轻松愉悦地学到东西(BP)。
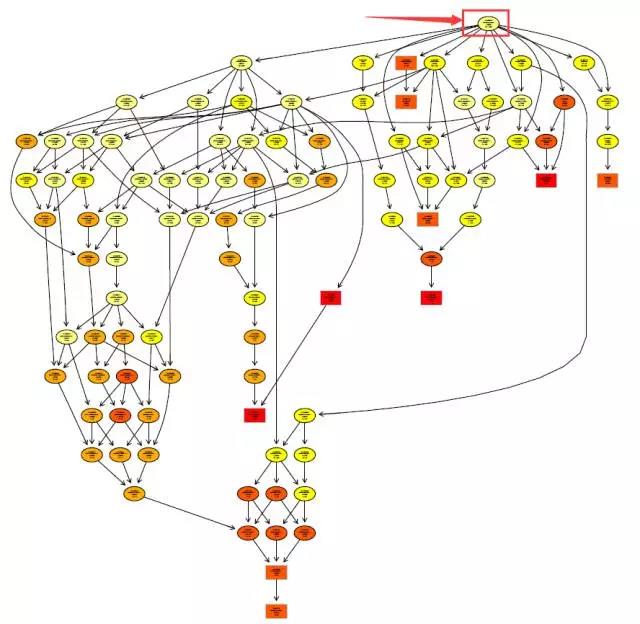
GO的术语是分层的,呈现出树状结构,上文提到的CC、MF和BP即为GO术语的最顶层,比如说下图是BP的分析结果树状图,最顶端即为BP。
通路分析 (Pathway Analysis)
一个生物学过程的实现会涉及到许多蛋白质,这些蛋白质合在一起就是一个通路。通路分析能够帮助我们更好地了解某个或某一些蛋白质在一个生物学过程中所扮演的角色。通路分析和GO都是对基因进行注释,那么为什么要对基因进行注释呢?因为基因说穿了其实是一串RNA,那么它的功能和结构虽然都是客观存在的,但是要如何描述这些客观的东西是基因注释所要解决的问题。
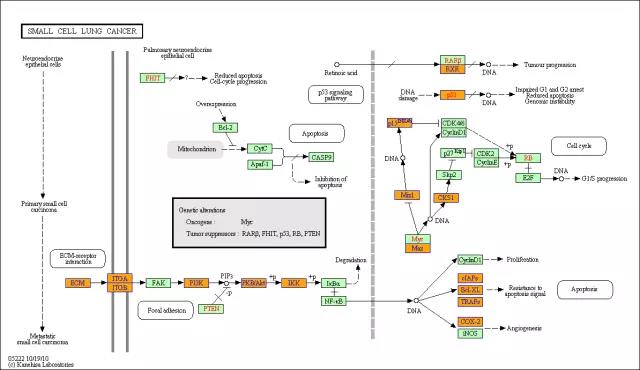
最常用的通路分析数据库是京都基因与基因组百科全书 (Kyoto Encyclopedia of Genes and Genomes, KEGG)。1995年,KEGG数据库项目由京都大学化学研究所教授Minoru Kanehisa领头启动。KEGG数据库是手工绘制的KEGG途径图的集合,每个途径图包含分子相互作用和反应的网络,将基因组中的基因与通路中的基因产物(主要是蛋白质)连接。KEGG pathway analysis即为将目的基因定位到KEGG途径图中的过程。下图为small cell lung cancer的KEGG途径图。
GO和KEGG pathway analysis都可以直接在DAVID网站上进行(https://david.ncifcrf.gov/),当然了也有许多软件和其它网站可以实现这一分析。GO和KEGG中涉及到的富集分析以及其中的数学算法这里就不赘述了。














